0x01 IO Error
大早上被群消息@炸醒了,起床看了下消息,所有昨天的报表数据没跑出来,老板和运营同学没看到昨天的报表表示很心慌,当然我也很心慌,但还是故作镇定回了句到公司解决,然后急冲冲洗漱完出门了。
到公司后看了下后台日志发现flume日志大量抛如下异常信息:

报的是IO Error,看样子是写数据失败了,之前没遇到过,Google下先(面向Google编程,哈哈~~),发现了有很多答案都提到一个配置dfs.datanode.max.xcievers,增大它的大小,于是尝试加到8092重启发现问题依旧,这时开始思考这个参数代表的意义,再次Google这个参数,其含义是datanode上进行数据传输时,最多能同时开启的连接数,一旦超过这个设置,datanode就会拒绝连接。并且hdfs dfsafmin -report就能实时显示其大小,当时每台datanode已超过8000连接数,而最大值是8192,算是定位到是什么因素其写入失败。但到底是什么影响其建了如此多的连接且没有释放呢。思考许久,突然想起时间戳有可能会导致这个问题,因为Flume将Kafka的消息写入到hdfs,hdfs上是按小时级分割存放。此时时间是按客户端时间戳,其配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| agent.sources.kafkaSource.interceptors = i1 i2 i3 i4 i5 i6
agent.sources.kafkaSource.interceptors.i1.type = regex_extractor
# 问题出在提取的时间戳actionTime上
agent.sources.kafkaSource.interceptors.i1.regex = \"actionTime\":(\\d+)
agent.sources.kafkaSource.interceptors.i1.serializers = s1
agent.sources.kafkaSource.interceptors.i1.serializers.s1.name = timestamp
agent.sources.kafkaSource.interceptors.i2.type = regex_extractor
agent.sources.kafkaSource.interceptors.i2.regex = \"businessId\":\"(.+?)\"
agent.sources.kafkaSource.interceptors.i2.serializers = s2
agent.sources.kafkaSource.interceptors.i2.serializers.s2.name = customName
agent.sources.kafkaSource.interceptors.i3.type = regex_extractor
agent.sources.kafkaSource.interceptors.i3.regex = \"sceneId\":\"(.+?)\"
agent.sources.kafkaSource.interceptors.i3.serializers = s3
agent.sources.kafkaSource.interceptors.i3.serializers.s3.name = sceneId
agent.sources.kafkaSource.interceptors.i4.type = regex_extractor
agent.sources.kafkaSource.interceptors.i4.regex = \"serviceName\":\"(.+?)\"
agent.sources.kafkaSource.interceptors.i4.serializers = s4
agent.sources.kafkaSource.interceptors.i4.serializers.s4.name = serviceName
agent.sources.kafkaSource.interceptors.i5.type = regex_extractor
agent.sources.kafkaSource.interceptors.i5.regex = \"logType\":\"(.+?)\"
agent.sources.kafkaSource.interceptors.i5.serializers = s5
agent.sources.kafkaSource.interceptors.i5.serializers.s5.name = logType
agent.sources.kafkaSource.interceptors.i6.type = regex_extractor
agent.sources.kafkaSource.interceptors.i6.regex = \"itemSetId\":\"(.+?)\"
agent.sources.kafkaSource.interceptors.i6.serializers = s6
agent.sources.kafkaSource.interceptors.i6.serializers.s6.name = itemSetId
agent.sinks.hdfs01.type = hdfs
agent.sinks.hdfs01.hdfs.path = hdfs://m1:8020/recom/log/%{customName}/%{sceneId}/%{serviceName}/%{logType}/%Y%m%d
|
问题有可能出在actionTime上,因为actionTime是客户端时间,而客户端时间有可能被用户篡改或者时区不对。为了验证这个问题,我们取了一下flume最终存档hdfs的数据(截图时间是7月11号):
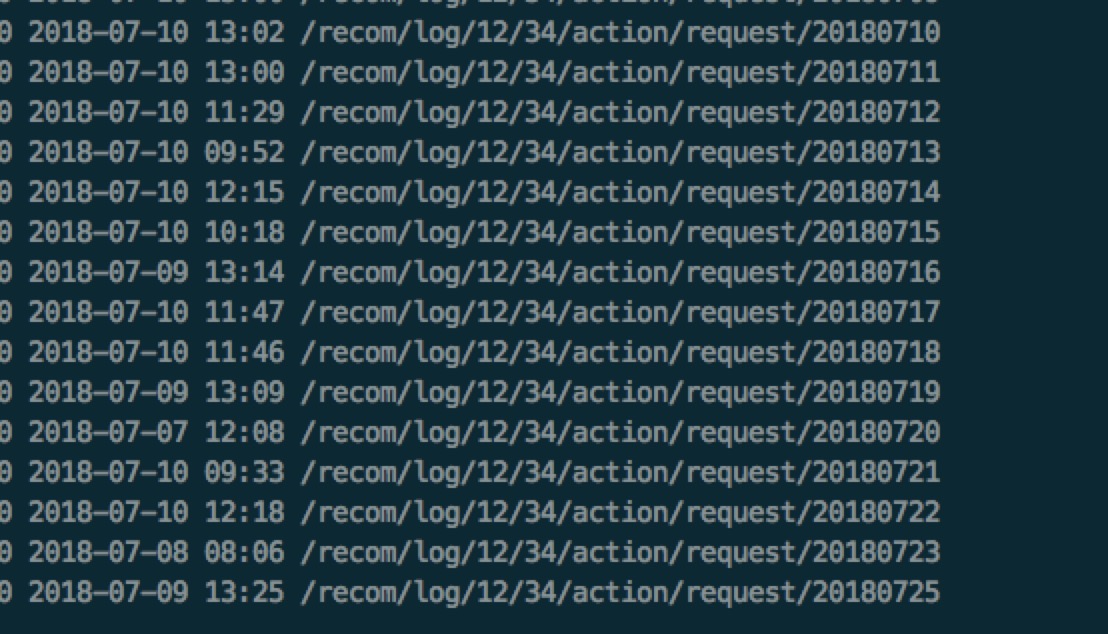
我们发现了有比7月11号日期更超前的日志产生,就是这个问题了。重新在复现下,我们只启动了6个flume消费Kafka的混入错误时间戳的日志,此时的连接数已高达4千多(下图中的xrecivers):
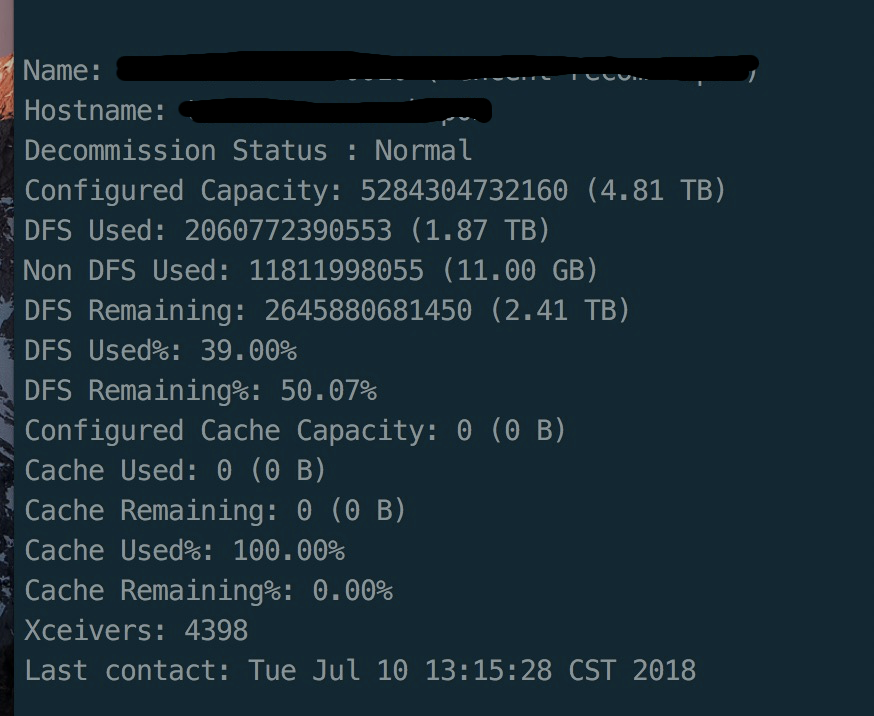
flume为什么因为带错误时间戳的日志而产生如此多的连接呢?
整理了一下整个过程,大体是这样,当一个小时内的时间戳错误的日志量(此时指处于不同小时的日志)超过一定量时(流量上来之后很容易发生),Flume会同时产生着么多量的到hdfs的socket连接,这些连接在1小时内不会释放(flume设置的日志轮转时间为1小时),而犹豫hdfs本身需要副本同步机制(设置的replica=2)导致这些机器也会生成同样数目的连接到其他datanode上,所以观察到的现象每台datanode上都有超高的连接数。
0x02 解决之道
明白了问题之后,其实很容易解决,即将客户端时间换成服务端时间即可,改完后启动10个flume连接数才占8百多
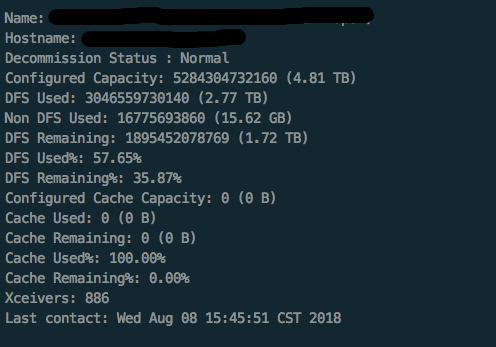
其实之前知道使用客户端时间会产生些问题,但按我的经验,日志时间出问题的分布是:客户端时间出问题的概率是20%,网络出错日志延迟发送的概率是80%。所以就采用了actionTime, 没想到真正造成毁灭性影响的是这20%。“墨菲定律”和“蝴蝶效应”再一次验证,希望以此为鉴。
0x03 优化
再flume做高可用架构之前,我们用最简单的办法对ETL部分做了下改善。
按1亿日PV来算的话,QPS大概在3000左右,峰值QPS在5000左右。
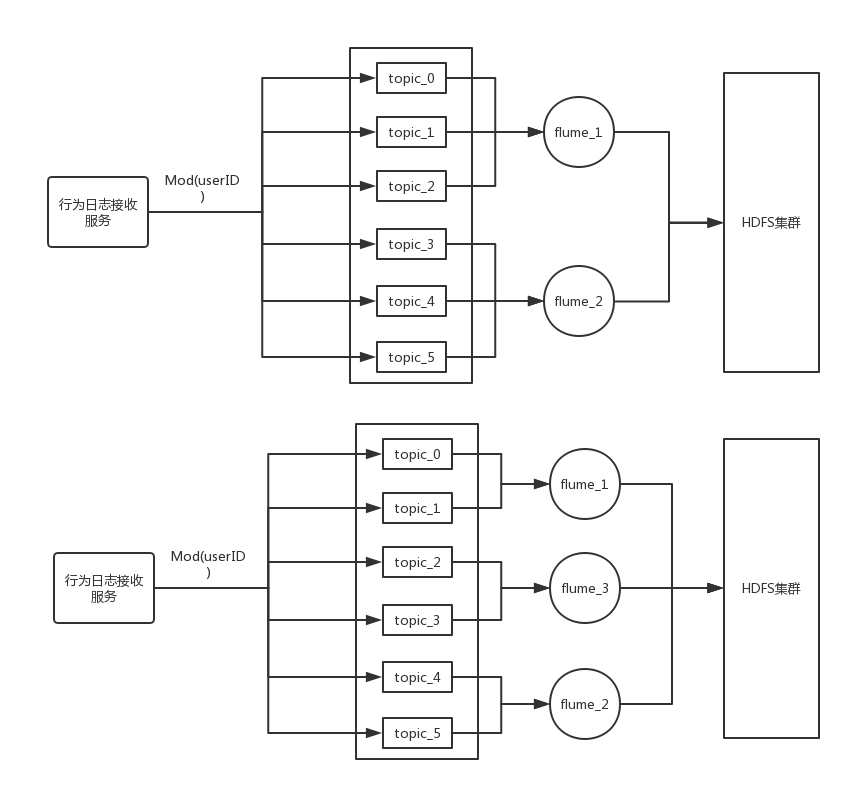
首先不再按新客户分配Kafka topic的方式,我们将Kafka topic限定在12个,将所有客户下的所有用户的请求按userID取模后打到不同的Topic上,这样的好处是给写操作做了负载均衡,结果是每个topic能扛住平均5000/12不到500的QPS,对于Kafka来说完全没有问题,另外部署三个flume去消费这12个Topic的数据,每个flume承载4个Kafka topic的数据,这样做的目的是为了方便扩展,当flume这出现瓶颈时很容易去横向扩展。下图示例了如何给flume做横向扩展(为了简化,图中的Kafka topic数取6)
0x04 总结
- 不要相信客户端
- 了解每个组件单节点资源的上限,并对可预见的流量做好资源分配。