大数据平台从0到1
写在前面:正好上周在给新同学介绍大数据平台,公司wiki上总结了一些文章,把这些文章整理整理,可以总成一篇比较系统性讲述数据平台的文章了。
0x01 数据流转
先介绍下业务数据流转过程,客户通过商家系统注册后,填入相关信息后,系统会给客户生成一个SDK。客户在自己的网站将此SDK埋入后,只要详情页加载事件被触发,SDK就会将详情页的信息抓取过来发到抓取后台,后台经过清洗之后做了两件事,一件事是直接保存到数据库中,另一件事是将这些信息发送到Kafka,Kakfa消费者端有一个服务实时的去做物料相似度计算,TF-IDF计算,关键词抽取等;除此外,SDK还会将这一条行为信息上报给行为接收服务,该服务会将行为日志经由Kafka发往到HDFS上,HDFS上的日志会按小时划分保存,同时会有一个Job定时去统计一个小时内的每个物品被点击的次数增量更新到物品表里。 这两步可以用来推热门和相关文章,完成冷启动的问题。
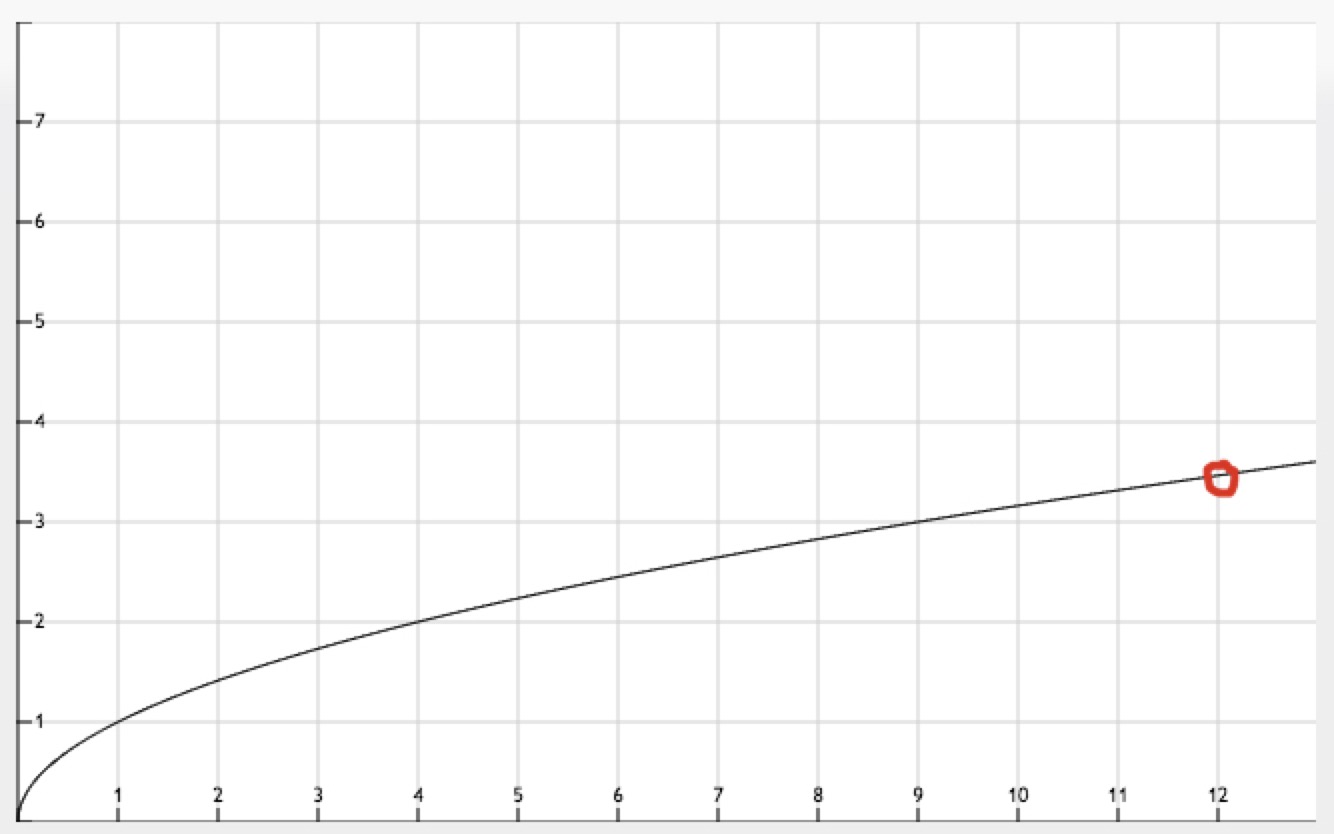
什么时候开始启动个性化推荐最适合呢,我们先思考下新增物料曲线图(如上图所示),横坐标为时间(单位:小时),纵坐标为新文章数(单位:百篇),会判断当斜率低于某个值时,则认为此时物料的的增长速度逼急极限(如上图红标处)。即说明网站的文章已基本采集完毕,此时开始触发模型workflow job,job自动拼接数据,建模,以及模型上线,此时可以按照算法工程师配置的流量规则将部分流量迁移到个性化推荐上。这样从客户接入到推荐个性化结果形成一个闭环。
0x02 搭建平台
为了将这条数据闭环打通,我们搭建了一套数据平台,我将整个大数据平台分为三层:ETL层、特征层和模型层。层级关系如下:
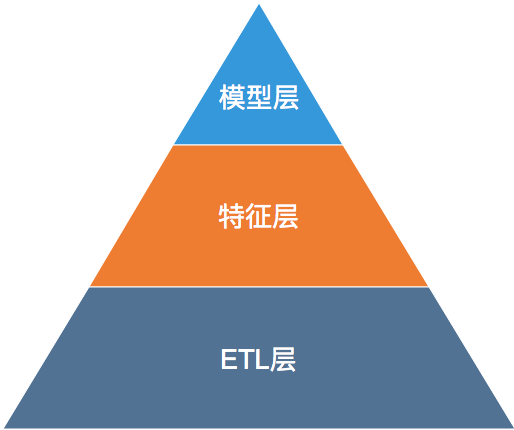
每一层的需要处理的工作如下:
ETL层:包括数据采集、数据中转、数据清洗、数据持久化。
统计特征层:包含用户实时统计特征、物品历史统计特征。
模型层:包含训练样本拼接、离线建模、线上预估。
具体架构图如下: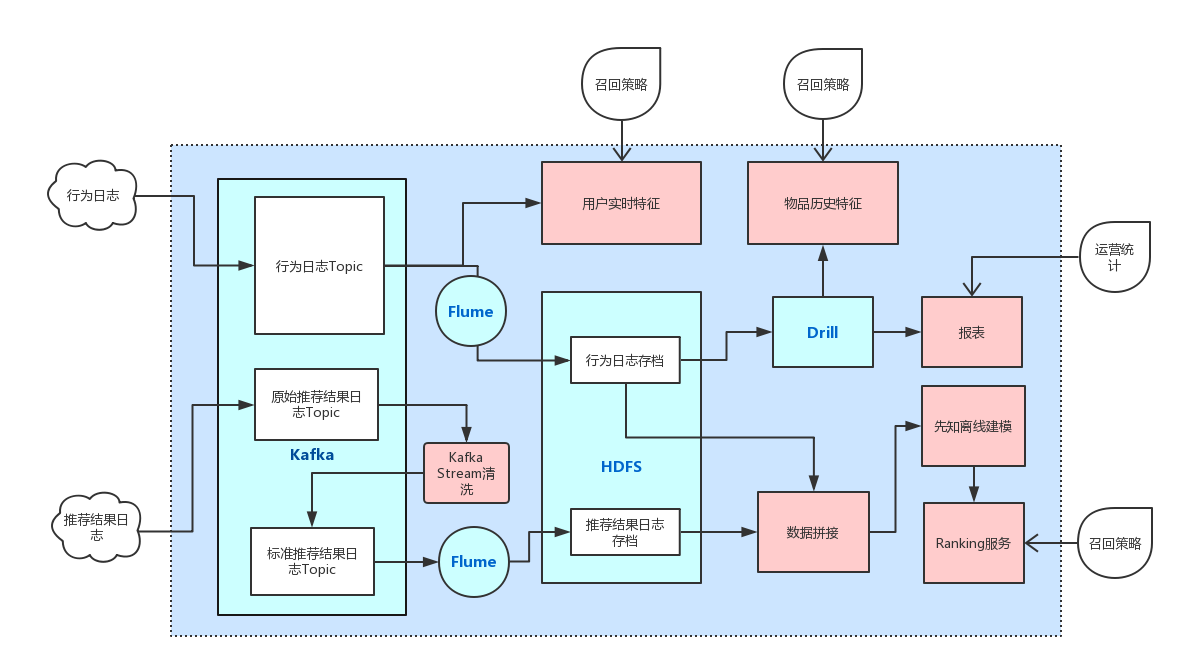
上图中绿色部分代表基础组件,Kafka作为数据中转组件,Flume作为Kafka和HDFS之间的Connector,HDFS作为最终日志存档的组件,Drill则用来做OLAP。
红色部分代表数据服务,Kafka Stream服务用来日志的清洗,用户实时特征服务从Kakfa中实时消费行为日志,根据配置生成相应的用户特征,供召回策略和建模使用。同时,基于Drill有两个服务,报表服务用来提供推荐效果反馈,当前最主要的指标的浏览PV,点击PV,CTR,阅读时长等。另一个服务是有个Job定时从行为日志中计算物品的相关特征(点击数,浏览数,CTR等)更新到物料库,主要用于做热度召回。
外部依赖部分,只依赖于推荐结果日志和行为日志。推荐结果日志由我们服务端记录,其意义是客户拉去推荐接口一次,我们将其请求信息,推荐结果以及中间数据封装在一个json中落盘。我们利用日志搜集工具Flume将其搜集到Kafka,不过该日志还需进一步要清洗成标准格式的数据。行为日志依靠SDK搜集,主要是对用户对一条物品产生的事件(展示,点击)生成的一条信息,其格式如下:
1 | { |
下游调用者部分,用户实时特征被调用两次:1.召回策略使用;2.在推荐结果返回之前调用该接口一次,将此时的用户特征做快照放入到推荐结果日志中(后面会讲,为了避免出现“特征穿越”)。物品历史特征会被召回策略调用,主要用于按热度召回。报表部分会讲整体推荐效果和细分渠道推荐效果按周、天、小时级别发送邮件。最后Ranking服务会被召回模块调用,召回出来的候选集经由Ranking服务打分排序返回,最终选择Top-N做为最终推荐结果返回给用户。
0x03 详细设计
针对每一层,我会开一篇文章详细说明这一层是如何设计的,包括ETL层搭建、特征层搭建、模型层搭建。
0x04 优化方向
- 对于ETL层来说,优化方向是整个数据底层组件的高可用性、高可靠性和实时性的提高。
- 对于特征层来说,优化方向是可配置化,支持多种特征存储库、多种特征格式。
- 对于模型来说,优化方向是拼接数据,建模的自动化,更好的AB机制。