ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
有一个说法是算法科学家会花70%的时间用在数据处理上,而数据处理最琐碎的部分也是在Transform部分,而对于我们当前业务来说,这算是一种解放,因为我们对基础数据格式做了严格定义,这使得我们花费相当少量的时间去做日志清洗。通常来说,这在大公司是很难做到的。因为各个业务的标准都不一样,推动他们修改成统一的格式需要花费巨大的成本。所以一个经验是在业务初期,大数据人员就应该主动参与数据标准和规范的制定,避免把坑留到后面。
0x01 ETL架构
本篇文章作为大数据平台的一部分,主要讨论大数据的ETL层是如何建立的。先放张图,
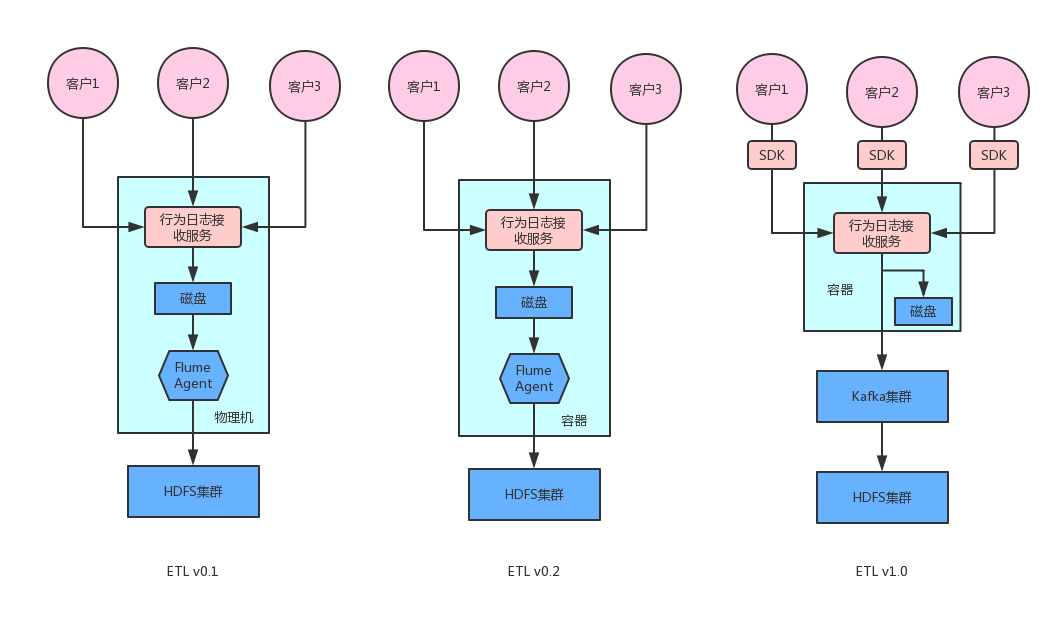
0.1版本中,客户将行为日志(展示、点击、收藏等)通过POST请求上传到我们的服务器,具体来说由行为日志接收服务负责接收客户传过来的行为并进行校验后持久化到本地磁盘,在该物理机上,我们还会布置一个flume agent,用于将磁盘上的日志实时传输到HDFS集群。0.1版本的优点在于简单,但是有两个问题暴露出来:1. 由于简单,所以其可靠性极差,如果挂掉需要手工重启,另外缺乏有效的监控。2.另外在物理机资源紧张的情况下,flume agent会占用内存,会对线上服务产生影响。
为了提高可靠性,从v0.2版本开始将flume-agent和action服务一起打到镜像中,部署在docker里,这样由K8S来同于管理,省去了很多手工维护的成本。将其但是随着客户越来越多,每个客户传过来的行为千差万别(比如feed流推荐传过来的是文章展示、点击、收藏、阅读时长等,视屏网站传过来的是视频播放,视频收藏,而社交推荐网站传过来的是喜欢、不喜欢等),受限于客户的技术水平,很多小客户对接接口是时间甚至要花费好几周。为了解决这个问题,v1.0版本将行为日志的上传交由sdk去完成,这样需要什么字段,全由我们自己控制,极大的降低了对接成本。
v1.0版本通过sdk收集用户行为,然后发往后端,后端接收到日志之后落盘的同时将该条日志发到Kafka消息队列,和之前相比,不需要flume再从硬盘上采集,流程上节省了一步,提高了日志传输的效率,同时接入Kafka更方便以后扩展流式应用,Kafka消费端会有Flume将日志输出到HDFS。
除了行为日志外,我们还需要收集推荐结果日志,推荐日志中包含的信息包含userID,文章信息,文章信息存放在mysql中,当我们将行为日志和推荐结果日志按traceID进行拼接,那为什么不直接将行为日志和物料库直接关联呢,需要对物料库数据做冗余呢,其实物料有可能会更新,如果不给当时的物品信息,物品特征,用户实时特征做快照的话,建模时会发生“时间穿越”的问题。
用未来的数据训练的模型去预测过去发生的事,称之为时间穿越。
比如,假设样本数据包含了7月份和8月份的用户行为数据,按照随机拆分,划分的结果将为训练集和测试集中都可能含有7月 和8月的数据,这样的数据在训练时没有问题,但是在预测评估时,会导致数据指标优于实际情况,例如,若真实的AUC应该 是0.7,那么在这样的数据集上评估出的结果就会大于0.7。
其中推荐结果日志格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| {
"reqEndMillis": 1534438801477,
"qs": "requestID=EbqIG2QC&userID=1qosEPzXZ&sceneID=1",
"req": "{\"itemID\":\"50347149\",\"uuid_tt_dd\":\"10_34194217130-1534438765984-908188\"}",
"result": [
{
"item": {
"publisher_id": "",
"title": "咦?八周学会<span style=\"color:#ca0c16;\">区块链开发</span>,程序员<span style=\"color:#ca0c16;\">转行</span>利器!",
"content": "区块链DApp开发学习路线图,月薪4万很轻松",
"publish_time": "2018-08-16 16:58:00",
"tag": "区块链;比特币;以太坊;区块链开发;加密猫;智能合约;私链;数字签名",
"item_id": "140"
},
"context": {
"channel": "channe1"
}
},
{
"item": {
"publisher_id": "",
"title": "厉害了!三个月如何学会Python<span style=\"color:#ca0c16;\">薪资</span>翻倍",
"content": "如何从8K提至20K月薪,你要掌握学习那些技能",
"publish_time": "2018-08-16 16:57:10",
"tag": "Python;python工程师;人工智能 ;Python爬虫技术;Python自动化运维;Python数据挖掘;图像处理",
"item_id": "160"
},
"context": {
"channel": "channel2"
}
}
],
"uss": {
"user_interest_channel": "***",
"user_interest_category_v1": "***",
"user_interest_itemId": "***",
"user_interest_tag": "***"
}
}
|
简单介绍下上面日志里的字段含义:
result:推荐结果字段,list结构,每一项代表一条推荐项,里面包含两项,item信息和context信息,context信息主要是方便统计,uss字段指用户的实时特征。
那怎样把这条日志清洗为标准的格式呢?将推荐项拆出来,已经将uss信息写到每一条推荐项里。使用Kafka Streams很方便就能处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
public class CleansingApplication {
public static void main(String[] args) {
Properties settings = new Properties();
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "clean");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-cluster");
settings.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
settings.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
settings.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
settings.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, WallclockTimestampExtractor.class);
settings.put(StreamsConfig.REQUEST_TIMEOUT_MS_CONFIG, 1000 * 60 * 5);
StreamsConfig config = new StreamsConfig(settings);
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> recommendLog = builder.stream("raw_recom_log");
JsonParser jsonparser = new JsonParser();
recommendLog.flatMap((k, v) -> {
List<KeyValue<String, String>> tmp = new ArrayList<>();
try {
JsonObject jsonObject = jsonparser.parse(v).getAsJsonObject();
JsonArray result = jsonObject.getAsJsonArray("result");
JsonObject uss = jsonObject.getAsJsonObject("uss");
for (Object o : result) {
JsonObject composedObj = (JsonObject) o;
JsonObject itemObj = composedObj.get("item").getAsJsonObject();
JsonObject contextObj = composedObj.get("context").getAsJsonObject();
Set<String> itemObjKeySet = itemObj.keySet();
for (String key : contextObj.keySet()) {
if (!itemObjKeySet.contains(key)) {
itemObj.add(key, contextObj.get(key));
}
}
for (String key : uss.keySet()) {
itemObj.add(key, uss.get(key));
}
itemObj.add("reqEndMillis", jsonObject.get("reqEndMillis"));
String qs = jsonObject.get("qs").getAsString();
Map<String, String> qsTokensMap = Splitter.on("&").withKeyValueSeparator("=").split(qs);
itemObj.addProperty("userId", qsTokensMap.get("userID"));
itemObj.add("qs", jsonObject.get("qs"));
tmp.add(new KeyValue<>(k, itemObj.toString()));
}
} catch (Exception e) {
System.out.println(e.getMessage());
}
return tmp;
}).to("standard_recom_log");
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
streams.close();
}
}));
}
}
|
当数据清洗完毕之后,数据重新导入到新的topic,接着可以使用flume作为kafka-hdfs-connector的将数据同步到HDFS上,Flume通过Interceptors很容易控制的从日志中提取相关字段作为hdfs存储路径,比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| #-------- timestamp interceptor 将event time提取出来-----------------
agent.sources.kafkaSource.interceptors = i1 i2 i3
agent.sources.kafkaSource.interceptors.i1.type = regex_extractor
agent.sources.kafkaSource.interceptors.i1.regex = \"logWriteTime\":(\\d+)
agent.sources.kafkaSource.interceptors.i1.serializers = s1
agent.sources.kafkaSource.interceptors.i1.serializers.s1.name = timestamp
agent.sources.kafkaSource.interceptors.i2.type = regex_extractor
agent.sources.kafkaSource.interceptors.i2.regex = \"sceneId\":\"(.+?)\"
agent.sources.kafkaSource.interceptors.i2.serializers = s2
agent.sources.kafkaSource.interceptors.i2.serializers.s2.name = sceneId
agent.sources.kafkaSource.interceptors.i3.type = regex_extractor
agent.sources.kafkaSource.interceptors.i3.regex = \"businessId\":\"(.+?)\"
agent.sources.kafkaSource.interceptors.i3.serializers = s3
agent.sources.kafkaSource.interceptors.i3.serializers.s3.name = businessId
agent.sinks.hdfsSink.type = hdfs
agent.sinks.hdfsSink.hdfs.path = hdfs://hdp01:8020/recom/action/%{businessId}/%{sceneId}/%Y%m%d
|
这里需要注意的是时间的提取只支持毫秒级Unix时间戳,如果时间是其他格式的话,比如nginx日志中2017-06-27 09:08:01这种格式的时间,可以参考这篇文章
0x02 监控
ETL层最重要的就是稳定性,而要提高稳定性就要求能及时的发现系统存在的问题,监控必不可少。首先对于组件的监控,
Flume需要监控的指标包含Source、channel、sink的监控,其中较为重要的是如下
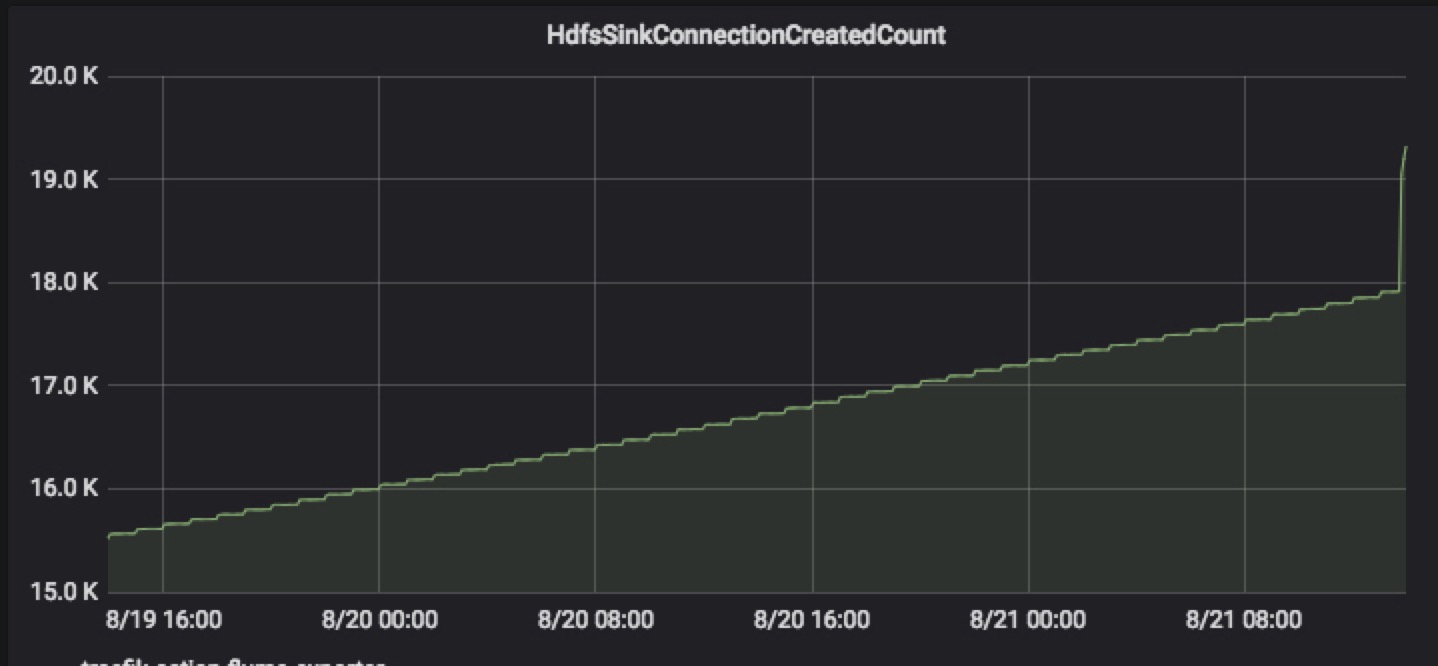
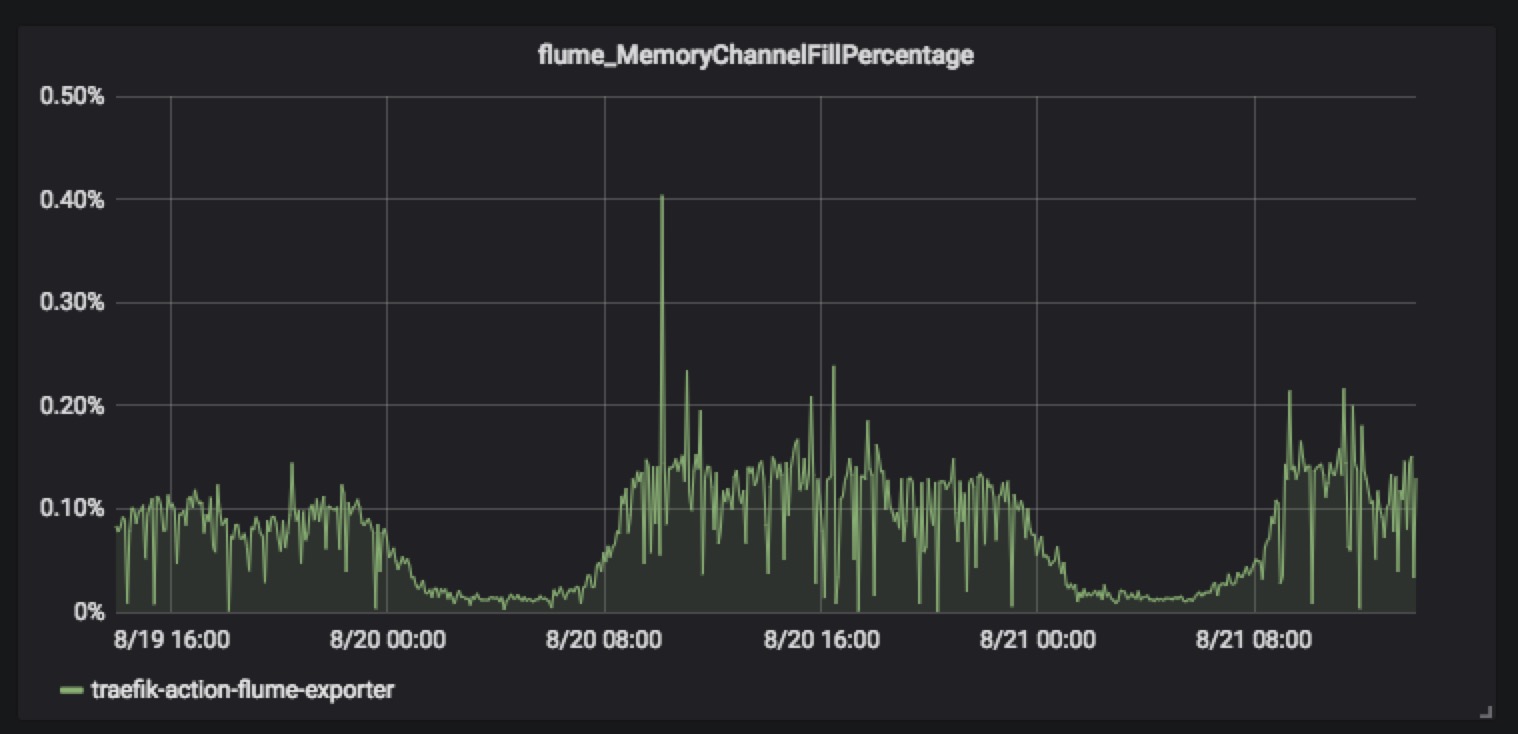
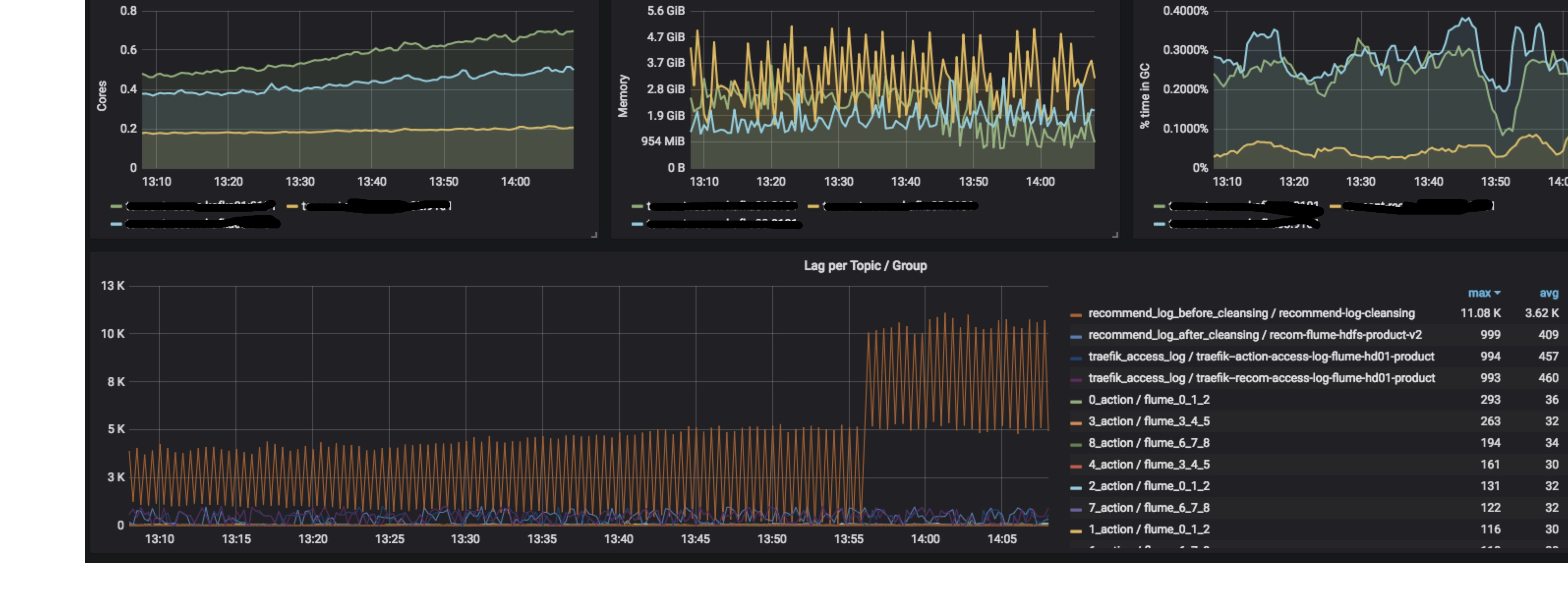
对于Kafka,JVM的监控(建议使用最新版本,1.0.0版本存在内存泄漏问题)和Lag的监控比较重要。
HDFS即主要监控namenode和datanode的状态
0x03 小结
本文主要介绍了ETL架构的组成部分,包括为什么演变成现在这样的架构,对于数据清洗,使用Kafka提供的Stream接口即可。除此之外,介绍了几个关键指标的监控。