人生苦短,我用SQL

这是第一篇技术博客,从以往的经历中开始说起吧。
在Qunar的时候,接手过W哥的一个活儿:给搜索结果页的结果排序,当时并没有用上现在流行的机器学习等技术,仅仅靠一些策略,离线计算各种分数最后汇总为每一个商品打一个分。当然这不是重点,重点是W哥的离线计算过程并没有使用任何分布式计算框架、也没有使用脚本,全量的数据仅靠的是几千行的SQL算分,可以说在Qunar,我见识到了“发挥到极致”的存储过程。你可以说在Mysql里做存储过程相比应用层写逻辑运行效率更高一些,但一个无法回避的问题是得为这一坨“存储过程”花很大的成本维护。
以致于很长的时间里,我见到复杂的SQL就会本能的反感。那为什么还会去拥抱SQL呢。其实更准确的描述是:我更愿意选择支持SQL-Like查询语言的NoSQL数据库。
那什么是NoSQL呢,看下维基百科的定义:
A NoSQL (originally referring to “non SQL” or “non relational”)[1] database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases. Such databases have existed since the late 1960s, but did not obtain the “NoSQL” moniker until a surge of popularity in the early twenty-first century,[2] triggered by the needs of Web 2.0 companies.[3][4][5] NoSQL databases are increasingly used in big data and real-time web applications.[6] NoSQL systems are also sometimes called “Not only SQL” to emphasize that they may support SQL-like query languages.
提炼出来重点即是:NoSQL系统也被称作“Not only SQL”, 用来强调支持SQL-Like查询语言的特性。
有人会有疑问,在HDFS上我完全可以用MapReduce去处理数据,可以使用Spark去处理数据,为什么非要把关系型数据库那一套查询语言搬到这来呢。
为了回答这个问题,我们回顾一下SQL的历史(截取了我认为比较重要的三段时间)
- 20世纪70年代初关系型数据库诞生。IBM研究院的Donald Chamberlin和Raymond Boyce两位博士意识到“计算机行业的成功很大程度上依赖于培养一种除了训练有素的计算机专家以外的用户“。为了解决查询语言过度复杂,于是他们重新设计了一种新的语言SQL,用他们自己的话来说:“这种语言用户使用更容易,不需要再参加数学或计算机程序方面的正规培训。”,毫无疑问,SQL在1974年被引入后一直成为关系型数据库的最主要语言。

- 1989年万维网出现,在随后的几十年里,随着互联网不断发展带来的数据指数级增长,关系型数据库逐渐无法应对大的负载压力。此时NoSQL运动开始兴起,Google发布MapReduce(2004年)和BigTable(2006年),Amazon发布了Dynamo(2007年),这些开创性的论文引导了一系列非关系型数据库的产生,包括Hadoop(2006)、Cassandra(2008)、MongoDB(2009)。NoSQL比这些作者想象的更受到社区的欢迎,一切看起来很美好是不是?问题随后出现了,开发者发现了不用SQL的局限性,每个NoSQL数据库都提供自己独特的查询语言,这意味着:要学习更多的语言,将这些数据库连接到应用程序的难度增加,导致大量胶水代码,缺乏第三方生态系统,要求企业必须开发自己的操作和可视化工具。(社区中有一些人比如DeWitt和Stonebraker在早期就看到了这些问题,经过时间的实战检验,越来越多的开发者也看到了这些问题)。
- 经历了黎明前的黑暗,社区终于选择拥抱SQL,此时的NoSQL已经变成了“不仅仅是SQL“,首先是Hadoop开始支持SQL接口,然后Google在第一篇Spanner论文中揭示这是基于SQL的查询语言,可以将一份数据复制到全球范围的多个数据中心,并保证数据的一致性,从而开创了可跨地理复制的SQL界面的数据库。而2017 SIGMOD会议中第二篇Spanner论文-“Spanner:成为一个SQL系统”将SQL的能力进一步加强。同年,Kafka Summit大会上Confluent宣布Kafka新的里程碑:KSQL,开启了SQL在流式数据的应用。
技术演进离不开实际需求的推动,经过社区的开发者们一步步实战,SQL终于被证明是NoSQL系统甚至是NewSQL系统中必不可少的交互语言,也可能未来会成为唯一的语言。(如果某一天第四代语言表达能力足够强)
SQL作为广大人民的选择,不是没有道理的。
一. SQL作为第四代语言,学习门槛降更低,应用范围更广。

SQL is the only widely used 4GL in commercial use today. Artificial intelligence languages are also classified as 4GL.
举个例子,
二. SQL接口的通用性正让其成为数据分析中的“窄腰”
在计算机网络中有一个概念叫“窄腰“(narrow waist),从下图中可以看到传输层和应用层的协议各式各样,但网络层只有IP协议,这样的设计是使得因特网得一成长和进化长达40年的重要原因之一。
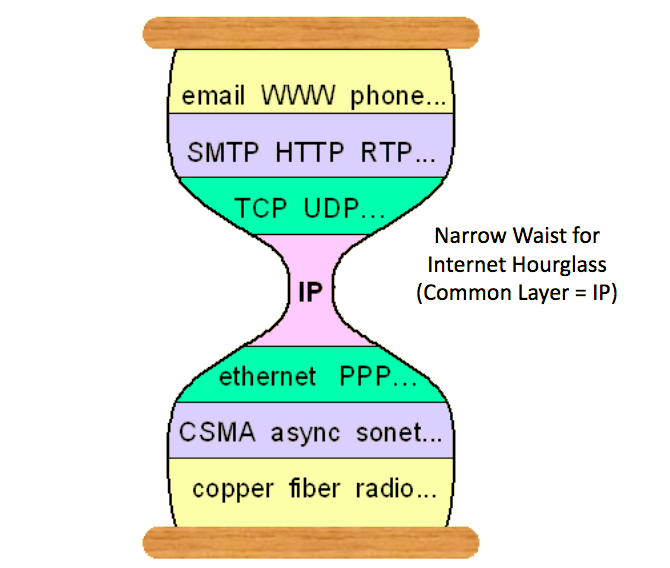
像网络一样,我们有一个复杂的堆栈,底层的基础设施和顶部的应用程序(当然还有一层即我们自己)。通常我们会编写了大量的胶水代码,使此堆栈工作。但是胶水代码可能很脆弱:需要维护和贴合。我们需要的是一个公共接口,允许这个堆栈的各个部分相互通信。这个行业已经标准化了。它能让不同层级之间的通信阻碍降到最小。
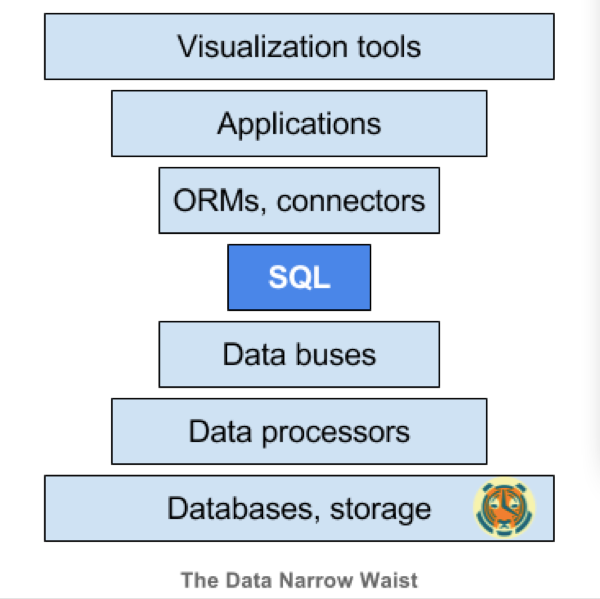
这就是SQL的力量。和IP一样,SQL也是一个公共接口。
三. 或许是最重要的,培训大家学习无数新语言的成本的是巨大的,而不仅仅是统一标准的重要性。
随着数据的增长,越来越多的人加入进来,数据科学家、工程师、数据分析人员等等、每一种职业都有专属的技能树,在面对海量数据时,选择SQL让我们聚焦在结果,而不去理会那下繁冗的无趣的过程。